# Marker
Marker converts documents to markdown, JSON, and HTML quickly and accurately.
- Converts PDF, image, PPTX, DOCX, XLSX, HTML, EPUB files in all languages
- Formats tables, forms, equations, inline math, links, references, and code blocks
- Extracts and saves images
- Removes headers/footers/other artifacts
- Extensible with your own formatting and logic
- Optionally boost accuracy with LLMs
- Works on GPU, CPU, or MPS
## Performance
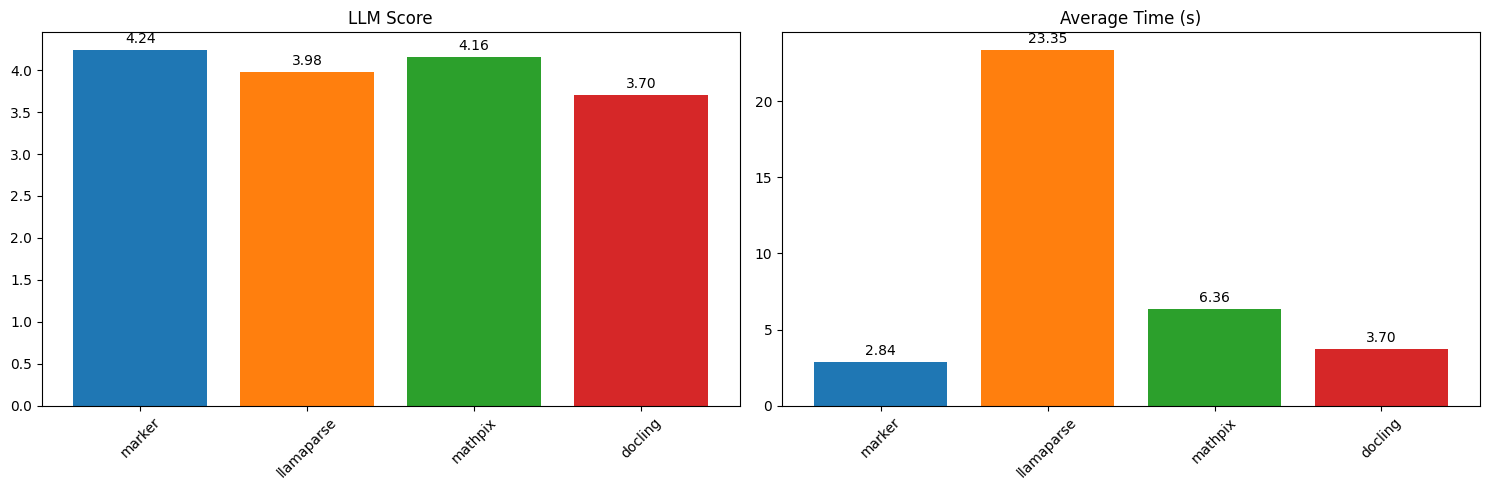 Marker benchmarks favorably compared to cloud services like Llamaparse and Mathpix, as well as other open source tools.
The above results are running single PDF pages serially. Marker is significantly faster when running in batch mode, with a projected throughput of 122 pages/second on an H100 (.18 seconds per page across 22 processes).
See [below](#benchmarks) for detailed speed and accuracy benchmarks, and instructions on how to run your own benchmarks.
## Hybrid Mode
For the highest accuracy, pass the `--use_llm` flag to use an LLM alongside marker. This will do things like merge tables across pages, handle inline math, format tables properly, and extract values from forms. It can use any gemini or ollama model. By default, it uses `gemini-2.0-flash`. See [below](#llm-services) for details.
Here is a table benchmark comparing marker, gemini flash alone, and marker with use_llm:
Marker benchmarks favorably compared to cloud services like Llamaparse and Mathpix, as well as other open source tools.
The above results are running single PDF pages serially. Marker is significantly faster when running in batch mode, with a projected throughput of 122 pages/second on an H100 (.18 seconds per page across 22 processes).
See [below](#benchmarks) for detailed speed and accuracy benchmarks, and instructions on how to run your own benchmarks.
## Hybrid Mode
For the highest accuracy, pass the `--use_llm` flag to use an LLM alongside marker. This will do things like merge tables across pages, handle inline math, format tables properly, and extract values from forms. It can use any gemini or ollama model. By default, it uses `gemini-2.0-flash`. See [below](#llm-services) for details.
Here is a table benchmark comparing marker, gemini flash alone, and marker with use_llm:
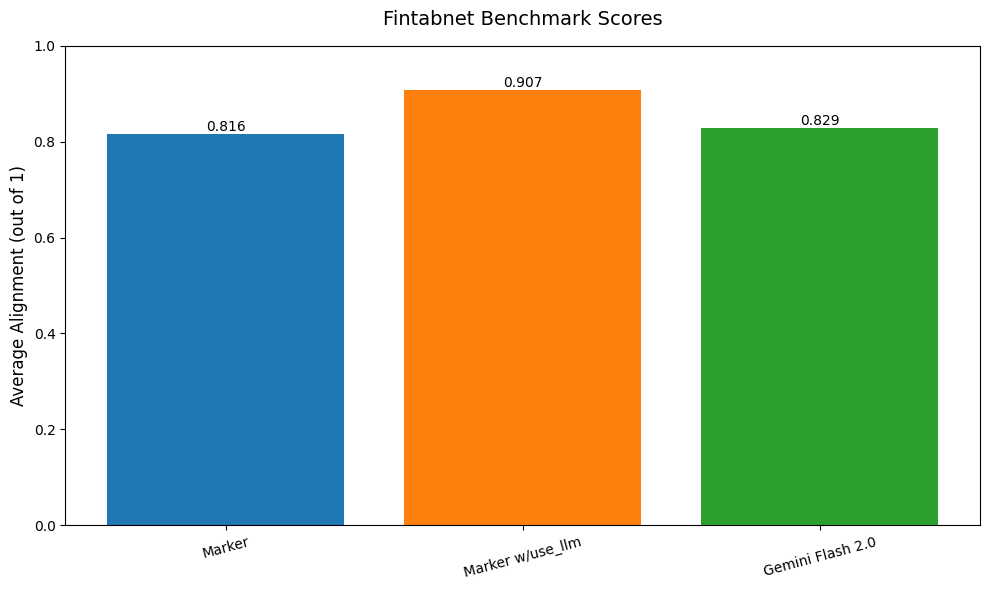 As you can see, the use_llm mode offers higher accuracy than marker or gemini alone.
## Examples
| PDF | File type | Markdown | JSON |
|-----|-----------|------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
| [Think Python](https://greenteapress.com/thinkpython/thinkpython.pdf) | Textbook | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/markdown/thinkpython/thinkpython.md) | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/json/thinkpython.json) |
| [Switch Transformers](https://arxiv.org/pdf/2101.03961.pdf) | arXiv paper | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/markdown/switch_transformers/switch_trans.md) | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/json/switch_trans.json) |
| [Multi-column CNN](https://arxiv.org/pdf/1804.07821.pdf) | arXiv paper | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/markdown/multicolcnn/multicolcnn.md) | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/json/multicolcnn.json) |
# Commercial usage
I want marker to be as widely accessible as possible, while still funding my development/training costs. Research and personal usage is always okay, but there are some restrictions on commercial usage.
The weights for the models are licensed `cc-by-nc-sa-4.0`, but I will waive that for any organization under \$5M USD in gross revenue in the most recent 12-month period AND under $5M in lifetime VC/angel funding raised. You also must not be competitive with the [Datalab API](https://www.datalab.to/). If you want to remove the GPL license requirements (dual-license) and/or use the weights commercially over the revenue limit, check out the options [here](https://www.datalab.to).
# Hosted API
There's a hosted API for marker available [here](https://www.datalab.to/):
- Supports PDFs, word documents, and powerpoints
- 1/4th the price of leading cloud-based competitors
- High uptime (99.99%), quality, and speed (around 15 seconds to convert a 250 page PDF)
# Community
[Discord](https://discord.gg//KuZwXNGnfH) is where we discuss future development.
# Installation
You'll need python 3.10+ and PyTorch. You may need to install the CPU version of torch first if you're not using a Mac or a GPU machine. See [here](https://pytorch.org/get-started/locally/) for more details.
Install with:
```shell
pip install marker-pdf
```
If you want to use marker on documents other than PDFs, you will need to install additional dependencies with:
```shell
pip install marker-pdf[full]
```
# Usage
First, some configuration:
- Your torch device will be automatically detected, but you can override this. For example, `TORCH_DEVICE=cuda`.
- Some PDFs, even digital ones, have bad text in them. Set the `force_ocr` flag to ensure your PDF runs through OCR, or the `strip_existing_ocr` to keep all digital text, and strip out any existing OCR text.
## Interactive App
I've included a streamlit app that lets you interactively try marker with some basic options. Run it with:
```shell
pip install streamlit
marker_gui
```
## Convert a single file
```shell
marker_single /path/to/file.pdf
```
You can pass in PDFs or images.
Options:
- `--output_dir PATH`: Directory where output files will be saved. Defaults to the value specified in settings.OUTPUT_DIR.
- `--output_format [markdown|json|html]`: Specify the format for the output results.
- `--paginate_output`: Paginates the output, using `\n\n{PAGE_NUMBER}` followed by `-` * 48, then `\n\n`
- `--use_llm`: Uses an LLM to improve accuracy. You must set your Gemini API key using the `GOOGLE_API_KEY` env var.
- `--redo_inline_math`: If you want the highest quality inline math conversion, use this along with `--use_llm`.
- `--disable_image_extraction`: Don't extract images from the PDF. If you also specify `--use_llm`, then images will be replaced with a description.
- `--page_range TEXT`: Specify which pages to process. Accepts comma-separated page numbers and ranges. Example: `--page_range "0,5-10,20"` will process pages 0, 5 through 10, and page 20.
- `--force_ocr`: Force OCR processing on the entire document, even for pages that might contain extractable text.
- `--strip_existing_ocr`: Remove all existing OCR text in the document and re-OCR with surya.
- `--debug`: Enable debug mode for additional logging and diagnostic information.
- `--processors TEXT`: Override the default processors by providing their full module paths, separated by commas. Example: `--processors "module1.processor1,module2.processor2"`
- `--config_json PATH`: Path to a JSON configuration file containing additional settings.
- `--languages TEXT`: Optionally specify which languages to use for OCR processing. Accepts a comma-separated list. Example: `--languages "en,fr,de"` for English, French, and German.
- `config --help`: List all available builders, processors, and converters, and their associated configuration. These values can be used to build a JSON configuration file for additional tweaking of marker defaults.
- `--converter_cls`: One of `marker.converters.pdf.PdfConverter` (default) or `marker.converters.table.TableConverter`. The `PdfConverter` will convert the whole PDF, the `TableConverter` will only extract and convert tables.
- `--llm_service`: Which llm service to use if `--use_llm` is passed. This defaults to `marker.services.gemini.GoogleGeminiService`.
- `--help`: see all of the flags that can be passed into marker. (it supports many more options then are listed above)
The list of supported languages for surya OCR is [here](https://github.com/VikParuchuri/surya/blob/master/surya/recognition/languages.py). If you don't need OCR, marker can work with any language.
## Convert multiple files
```shell
marker /path/to/input/folder --workers 4
```
- `marker` supports all the same options from `marker_single` above.
- `--workers` is the number of conversion workers to run simultaneously. This is set to 5 by default, but you can increase it to increase throughput, at the cost of more CPU/GPU usage. Marker will use 5GB of VRAM per worker at the peak, and 3.5GB average.
## Convert multiple files on multiple GPUs
```shell
NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
```
- `NUM_DEVICES` is the number of GPUs to use. Should be `2` or greater.
- `NUM_WORKERS` is the number of parallel processes to run on each GPU.
## Use from python
See the `PdfConverter` class at `marker/converters/pdf.py` function for additional arguments that can be passed.
```python
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = PdfConverter(
artifact_dict=create_model_dict(),
)
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
```
`rendered` will be a pydantic basemodel with different properties depending on the output type requested. With markdown output (default), you'll have the properties `markdown`, `metadata`, and `images`. For json output, you'll have `children`, `block_type`, and `metadata`.
### Custom configuration
You can pass configuration using the `ConfigParser`. To see all available options, do `marker_single --help`.
```python
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.config.parser import ConfigParser
config = {
"output_format": "json",
"ADDITIONAL_KEY": "VALUE"
}
config_parser = ConfigParser(config)
converter = PdfConverter(
config=config_parser.generate_config_dict(),
artifact_dict=create_model_dict(),
processor_list=config_parser.get_processors(),
renderer=config_parser.get_renderer(),
llm_service=config_parser.get_llm_service()
)
rendered = converter("FILEPATH")
```
### Extract blocks
Each document consists of one or more pages. Pages contain blocks, which can themselves contain other blocks. It's possible to programmatically manipulate these blocks.
Here's an example of extracting all forms from a document:
```python
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.schema import BlockTypes
converter = PdfConverter(
artifact_dict=create_model_dict(),
)
document = converter.build_document("FILEPATH")
forms = document.contained_blocks((BlockTypes.Form,))
```
Look at the processors for more examples of extracting and manipulating blocks.
## Other converters
You can also use other converters that define different conversion pipelines:
### Extract tables
The `TableConverter` will only convert and extract tables:
```python
from marker.converters.table import TableConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = TableConverter(
artifact_dict=create_model_dict(),
)
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
```
This takes all the same configuration as the PdfConverter. You can specify the configuration `force_layout_block=Table` to avoid layout detection and instead assume every page is a table. Set `output_format=json` to also get cell bounding boxes.
You can also run this via the CLI with
```shell
marker_single FILENAME --use_llm --force_layout_block Table --converter_cls marker.converters.table.TableConverter --output_format json
```
# Output Formats
## Markdown
Markdown output will include:
- image links (images will be saved in the same folder)
- formatted tables
- embedded LaTeX equations (fenced with `$$`)
- Code is fenced with triple backticks
- Superscripts for footnotes
## HTML
HTML output is similar to markdown output:
- Images are included via `img` tags
- equations are fenced with `
As you can see, the use_llm mode offers higher accuracy than marker or gemini alone.
## Examples
| PDF | File type | Markdown | JSON |
|-----|-----------|------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
| [Think Python](https://greenteapress.com/thinkpython/thinkpython.pdf) | Textbook | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/markdown/thinkpython/thinkpython.md) | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/json/thinkpython.json) |
| [Switch Transformers](https://arxiv.org/pdf/2101.03961.pdf) | arXiv paper | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/markdown/switch_transformers/switch_trans.md) | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/json/switch_trans.json) |
| [Multi-column CNN](https://arxiv.org/pdf/1804.07821.pdf) | arXiv paper | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/markdown/multicolcnn/multicolcnn.md) | [View](https://github.com/VikParuchuri/marker/blob/master/data/examples/json/multicolcnn.json) |
# Commercial usage
I want marker to be as widely accessible as possible, while still funding my development/training costs. Research and personal usage is always okay, but there are some restrictions on commercial usage.
The weights for the models are licensed `cc-by-nc-sa-4.0`, but I will waive that for any organization under \$5M USD in gross revenue in the most recent 12-month period AND under $5M in lifetime VC/angel funding raised. You also must not be competitive with the [Datalab API](https://www.datalab.to/). If you want to remove the GPL license requirements (dual-license) and/or use the weights commercially over the revenue limit, check out the options [here](https://www.datalab.to).
# Hosted API
There's a hosted API for marker available [here](https://www.datalab.to/):
- Supports PDFs, word documents, and powerpoints
- 1/4th the price of leading cloud-based competitors
- High uptime (99.99%), quality, and speed (around 15 seconds to convert a 250 page PDF)
# Community
[Discord](https://discord.gg//KuZwXNGnfH) is where we discuss future development.
# Installation
You'll need python 3.10+ and PyTorch. You may need to install the CPU version of torch first if you're not using a Mac or a GPU machine. See [here](https://pytorch.org/get-started/locally/) for more details.
Install with:
```shell
pip install marker-pdf
```
If you want to use marker on documents other than PDFs, you will need to install additional dependencies with:
```shell
pip install marker-pdf[full]
```
# Usage
First, some configuration:
- Your torch device will be automatically detected, but you can override this. For example, `TORCH_DEVICE=cuda`.
- Some PDFs, even digital ones, have bad text in them. Set the `force_ocr` flag to ensure your PDF runs through OCR, or the `strip_existing_ocr` to keep all digital text, and strip out any existing OCR text.
## Interactive App
I've included a streamlit app that lets you interactively try marker with some basic options. Run it with:
```shell
pip install streamlit
marker_gui
```
## Convert a single file
```shell
marker_single /path/to/file.pdf
```
You can pass in PDFs or images.
Options:
- `--output_dir PATH`: Directory where output files will be saved. Defaults to the value specified in settings.OUTPUT_DIR.
- `--output_format [markdown|json|html]`: Specify the format for the output results.
- `--paginate_output`: Paginates the output, using `\n\n{PAGE_NUMBER}` followed by `-` * 48, then `\n\n`
- `--use_llm`: Uses an LLM to improve accuracy. You must set your Gemini API key using the `GOOGLE_API_KEY` env var.
- `--redo_inline_math`: If you want the highest quality inline math conversion, use this along with `--use_llm`.
- `--disable_image_extraction`: Don't extract images from the PDF. If you also specify `--use_llm`, then images will be replaced with a description.
- `--page_range TEXT`: Specify which pages to process. Accepts comma-separated page numbers and ranges. Example: `--page_range "0,5-10,20"` will process pages 0, 5 through 10, and page 20.
- `--force_ocr`: Force OCR processing on the entire document, even for pages that might contain extractable text.
- `--strip_existing_ocr`: Remove all existing OCR text in the document and re-OCR with surya.
- `--debug`: Enable debug mode for additional logging and diagnostic information.
- `--processors TEXT`: Override the default processors by providing their full module paths, separated by commas. Example: `--processors "module1.processor1,module2.processor2"`
- `--config_json PATH`: Path to a JSON configuration file containing additional settings.
- `--languages TEXT`: Optionally specify which languages to use for OCR processing. Accepts a comma-separated list. Example: `--languages "en,fr,de"` for English, French, and German.
- `config --help`: List all available builders, processors, and converters, and their associated configuration. These values can be used to build a JSON configuration file for additional tweaking of marker defaults.
- `--converter_cls`: One of `marker.converters.pdf.PdfConverter` (default) or `marker.converters.table.TableConverter`. The `PdfConverter` will convert the whole PDF, the `TableConverter` will only extract and convert tables.
- `--llm_service`: Which llm service to use if `--use_llm` is passed. This defaults to `marker.services.gemini.GoogleGeminiService`.
- `--help`: see all of the flags that can be passed into marker. (it supports many more options then are listed above)
The list of supported languages for surya OCR is [here](https://github.com/VikParuchuri/surya/blob/master/surya/recognition/languages.py). If you don't need OCR, marker can work with any language.
## Convert multiple files
```shell
marker /path/to/input/folder --workers 4
```
- `marker` supports all the same options from `marker_single` above.
- `--workers` is the number of conversion workers to run simultaneously. This is set to 5 by default, but you can increase it to increase throughput, at the cost of more CPU/GPU usage. Marker will use 5GB of VRAM per worker at the peak, and 3.5GB average.
## Convert multiple files on multiple GPUs
```shell
NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
```
- `NUM_DEVICES` is the number of GPUs to use. Should be `2` or greater.
- `NUM_WORKERS` is the number of parallel processes to run on each GPU.
## Use from python
See the `PdfConverter` class at `marker/converters/pdf.py` function for additional arguments that can be passed.
```python
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = PdfConverter(
artifact_dict=create_model_dict(),
)
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
```
`rendered` will be a pydantic basemodel with different properties depending on the output type requested. With markdown output (default), you'll have the properties `markdown`, `metadata`, and `images`. For json output, you'll have `children`, `block_type`, and `metadata`.
### Custom configuration
You can pass configuration using the `ConfigParser`. To see all available options, do `marker_single --help`.
```python
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.config.parser import ConfigParser
config = {
"output_format": "json",
"ADDITIONAL_KEY": "VALUE"
}
config_parser = ConfigParser(config)
converter = PdfConverter(
config=config_parser.generate_config_dict(),
artifact_dict=create_model_dict(),
processor_list=config_parser.get_processors(),
renderer=config_parser.get_renderer(),
llm_service=config_parser.get_llm_service()
)
rendered = converter("FILEPATH")
```
### Extract blocks
Each document consists of one or more pages. Pages contain blocks, which can themselves contain other blocks. It's possible to programmatically manipulate these blocks.
Here's an example of extracting all forms from a document:
```python
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.schema import BlockTypes
converter = PdfConverter(
artifact_dict=create_model_dict(),
)
document = converter.build_document("FILEPATH")
forms = document.contained_blocks((BlockTypes.Form,))
```
Look at the processors for more examples of extracting and manipulating blocks.
## Other converters
You can also use other converters that define different conversion pipelines:
### Extract tables
The `TableConverter` will only convert and extract tables:
```python
from marker.converters.table import TableConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = TableConverter(
artifact_dict=create_model_dict(),
)
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
```
This takes all the same configuration as the PdfConverter. You can specify the configuration `force_layout_block=Table` to avoid layout detection and instead assume every page is a table. Set `output_format=json` to also get cell bounding boxes.
You can also run this via the CLI with
```shell
marker_single FILENAME --use_llm --force_layout_block Table --converter_cls marker.converters.table.TableConverter --output_format json
```
# Output Formats
## Markdown
Markdown output will include:
- image links (images will be saved in the same folder)
- formatted tables
- embedded LaTeX equations (fenced with `$$`)
- Code is fenced with triple backticks
- Superscripts for footnotes
## HTML
HTML output is similar to markdown output:
- Images are included via `img` tags
- equations are fenced with `